Getting the most out of AI credits in Warp

Note (Oct 9, 2025): We’ve updated some content in this post to reflect our recent product terminology change from “requests” to “credits.” To learn more about this update around AI usage transparency, see our blog post on making AI usage more transparent.
Whether you’re a long-time Warp fan, or you’re just getting started with prompt-driven development, you may be asking: what exactly is a credit in Warp? Why do some of my AI interactions cost one credit, while others cost a dozen? How do I know what plan (Pro/Turbo/Lightspeed) is right for me? In this blog post, I’ll pull back the curtain on how credits work, so that you can maximize whatever plan fits you the best!
By the way, my name’s Jeff – I’m one of the Tech Leads here at Warp. If you love thinking about pricing as much as I do, or if you want to build the future of agentic development, we’re hiring!
What is an AI credit?
Each time you use Warp’s AI features, credits are consumed based on the interaction. At least one credit is used per request to an AI agent. For example, a simple prompt like “Create a new branch called jeff/my-cool-feature” might use one credit. In fact, in my testing, it totally does! You can check the number of credits used since your last user input to the agent via the informational tooltip at the end of the conversation.
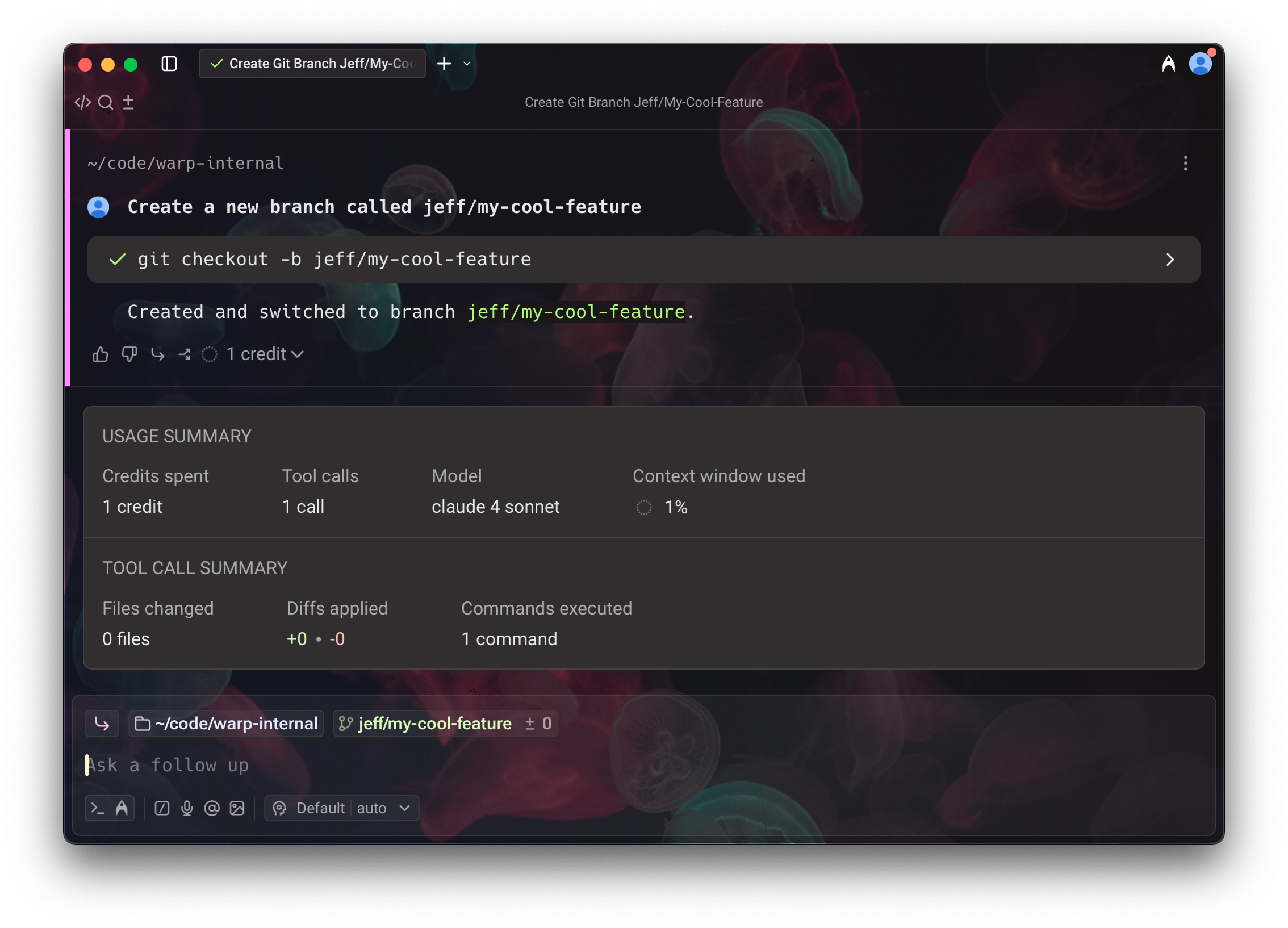
It’s important to note that you never use AI credits for running shell commands on your own – only when talking to agents!
What goes into calculating a credit?
In general, there are a few critical inputs to how many credits a query will consume:
- What model are you using? More premium models = more credits
- How much context are you attaching to your request? More context = more credits
- How deeply does the agent need to scan your codebase, filesystem, or other sources of information to provide an answer to your query? More context gathering = more credits
- How many back-and-forths does it take to complete the task? Longer conversations = more credits
- How often are you switching models in the middle of a conversation? More switches = more credits
- How recent is the conversation? Newer conversations are more likely to be cached with our model providers, which allows Warp to charge fewer credits to you. More cache misses = more credits
Making the right tradeoffs
From the previous section, it might sound like making simple requests with cheap, weak models and zero context is the best way to ration your credits. And in one way, it is!
However, my hope with this blog post isn’t to make you switch to some cheap model from 4 years ago to complete your agentic tasks. In fact, I almost never use anything but the most state-of-the-art models when I’m using Warp to build Warp. Why? Because I want high quality responses. I’m willing to use a few extra credits to make sure that the answer I get from an agent is actually useful. Otherwise, I might have burned through fewer credits, but I still need to keep collaborating with an agent to accomplish my task.
With the rest of this post, I want to give tips on a few ways that you can keep the quality of the LLM responses quite high while still using as few credits as possible. The best of both worlds!
Tip 1: Keep conversations short and focused
I know “prompt engineer” as a job title is a bit of a meme nowadays, but truly, how you prompt an agent matters a lot. As the human in the loop, you have the important task of telling an agent what it needs to know – and only what it needs to know – to accomplish a task. If you tell an agent “find and fix all bugs in my app”, it will likely have a hard time gathering context and iterating on a working solution. It could get stuck in loops as it tries to convince itself that it built the appropriate functionality. It might run the wrong commands to test against your codebase or search for an overly-broad set of files. All of these turns will cost precious credits and aren’t getting you closer to the bug-free app you want.
Instead, include as much relevant information in your user query as possible. Let’s say you’re new to a codebase and you want an explanation of how events are handled in the application. If you can provide the agent with a file that seems relevant, you might skip the time (and credits!) the agent would have otherwise spent gathering enough context to find that file. Or, if you have the exact structure of the solution in mind, describe that to the agent – tell it what files it should create and where, how you want responsibilities separated, and what test cases it should cover. This will keep it on track and ensure that the final output most closely matches what you expect.
Tip 2: Start new conversations for new tasks
Let’s say you just asked Warp to build a new feature in your React app for you. It completes the task and summarizes what it did. When you go to deploy it, you realize that your gcloud binary is corrupted, and you want help fixing that too. If you follow up on the summary from the React conversation, not only might you confuse the agent by talking about a totally different task than the one it built up a lot of context trying to understand, but by continuing an irrelevant conversation, you’ll use a lot more credits, too! Instead, use the conversation selector in the input to start a new conversation, or open up a new pane or tab.
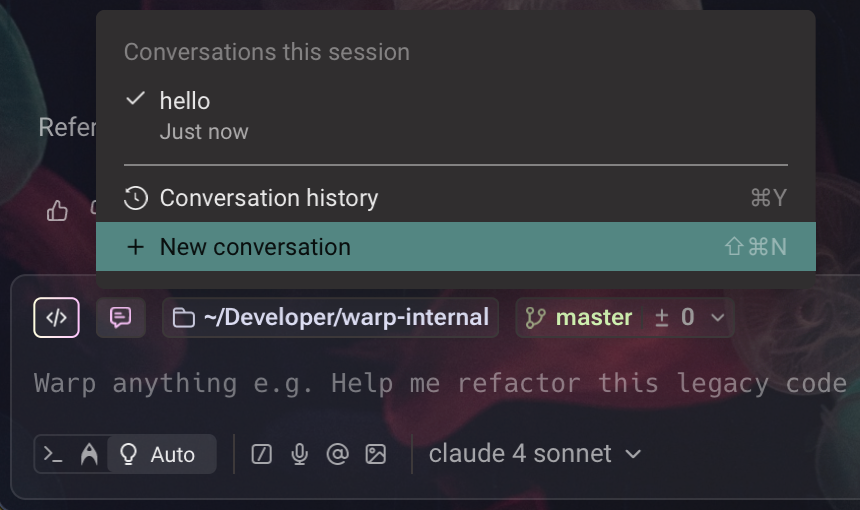
Warp includes a feature which will attempt to detect when a conversation has switched subjects sufficiently such that it’s best to start a new conversation, instead of continuing the previous one. However, you know best as to when the previous conversation is no longer relevant to your current ask!
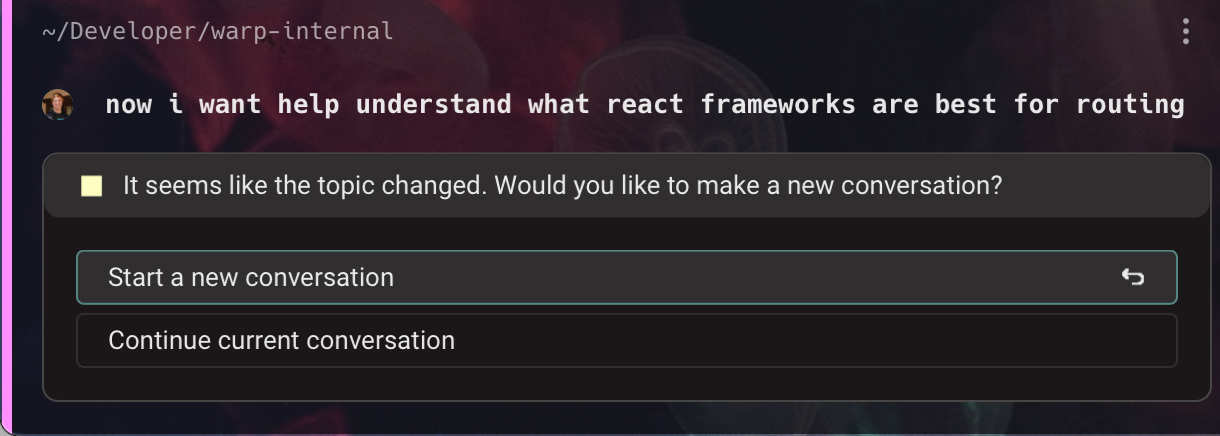
Tip 3: Be careful about what context you include
Warp makes it easy to select one or many blocks and add them to AI queries. For example, you may have a crazy Rust project that prints out thousands of lines of output when building, only for the last 5 lines of output to show a missing semicolon on one line of one file. If this happens, consider selecting the relevant text in the output and asking your query with “selected text attached” rather than attaching the entire block. This will reduce the number of credits, and has the additional benefit of keeping the agent more focused on the relevant parts of the issue!
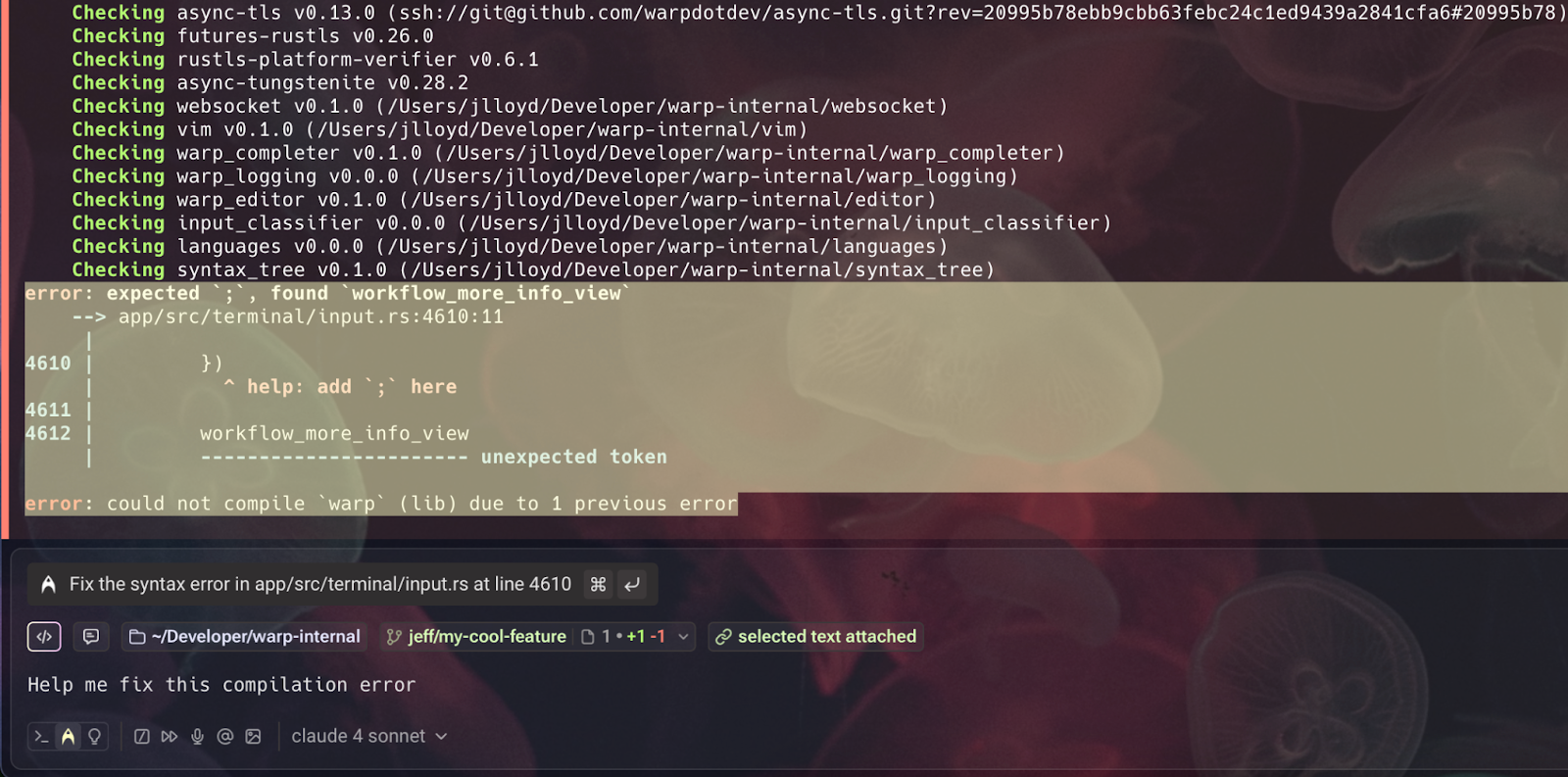
Blocks with tons of lines of output are just one kind of context that can blow up your request size; also be careful about attaching very large images or referencing files with thousands of lines. Again, the more specific and targeted your user queries are, the less chance the agent will have of adding context that contributes to large request usage.
Tip 4: Leverage rules and WARP.md
In Warp, you can define Rules to specify guidelines to an agent as to how you want it to operate. For example, you can tell an agent that it should always use gt over git, or that it should always check compilation by running cargo check in the root of the project, or that all public API methods it generates should include doc comments. You can expand this further with a WARP.md file in your repository, which acts as a project-level rule definition file, letting you and your teammates define a shared set of rules in source control.
As is a recurring theme with this blog post, using rules will keep agents on track and less likely to go down paths that require you to correct them. And you’ll spend less time manually correcting or linting their work. A little bit of pre-work will save you credits and time!’
Tip 5: Avoid switching models too often mid-conversation
Warp supports a bunch of model providers like OpenAI’s GPT-5 and Anthropic’s Claude Sonnet 4. All of them have some functionality related to temporary caching of conversations; any cache hits incur a smaller cost to Warp, and Warp passes that savings onto you in the form of fewer credits. You don’t need to fully understand the internals, but the point is this: if you switch models in the middle of a conversation, even between models from the same company, your conversation will definitely not be cached, and so more credits will be consumed. Sometimes, you might find this is an acceptable tradeoff; for example, you might find that GPT-5 does a great job explaining code, but when it comes time to implement a fix, Sonnet 4 is a better choice in your codebase. Just be careful about swapping too often!
Wrapping up
I hope this blog post helped demystify some of what goes on behind the scenes when you’re building features with Warp! It’s definitely been a learning experience for me as well – it took me a long time to learn about how LLMs worked and build up my own intuition for what queries would likely cost a lot of credits. I encourage everyone to try prompt-driven development in Warp and build up that same intuition, and use the tips above to avoid making the same mistakes I did!
Related articles

May 20, 2026 · 6 min
Bring your own inference to Warp
Today we’re releasing one of the most requested updates from the Warp community: more control over inference.

May 19, 2026 · 6 min
A single pane of glass for managing all of your cloud agents
With Oz, engineering teams can now integrate, orchestrate, control, and improve any cloud agent at scale including Claude Code, Codex, Warp Agent, and whatever comes next.

Apr 28, 2026 · 7 min
Warp is now open-source
Warp is now open-source, and the community can participate in building it using an agent-first workflow managed by Oz, our cloud agent orchestration platform.