Building the MCP Search Tool for any model

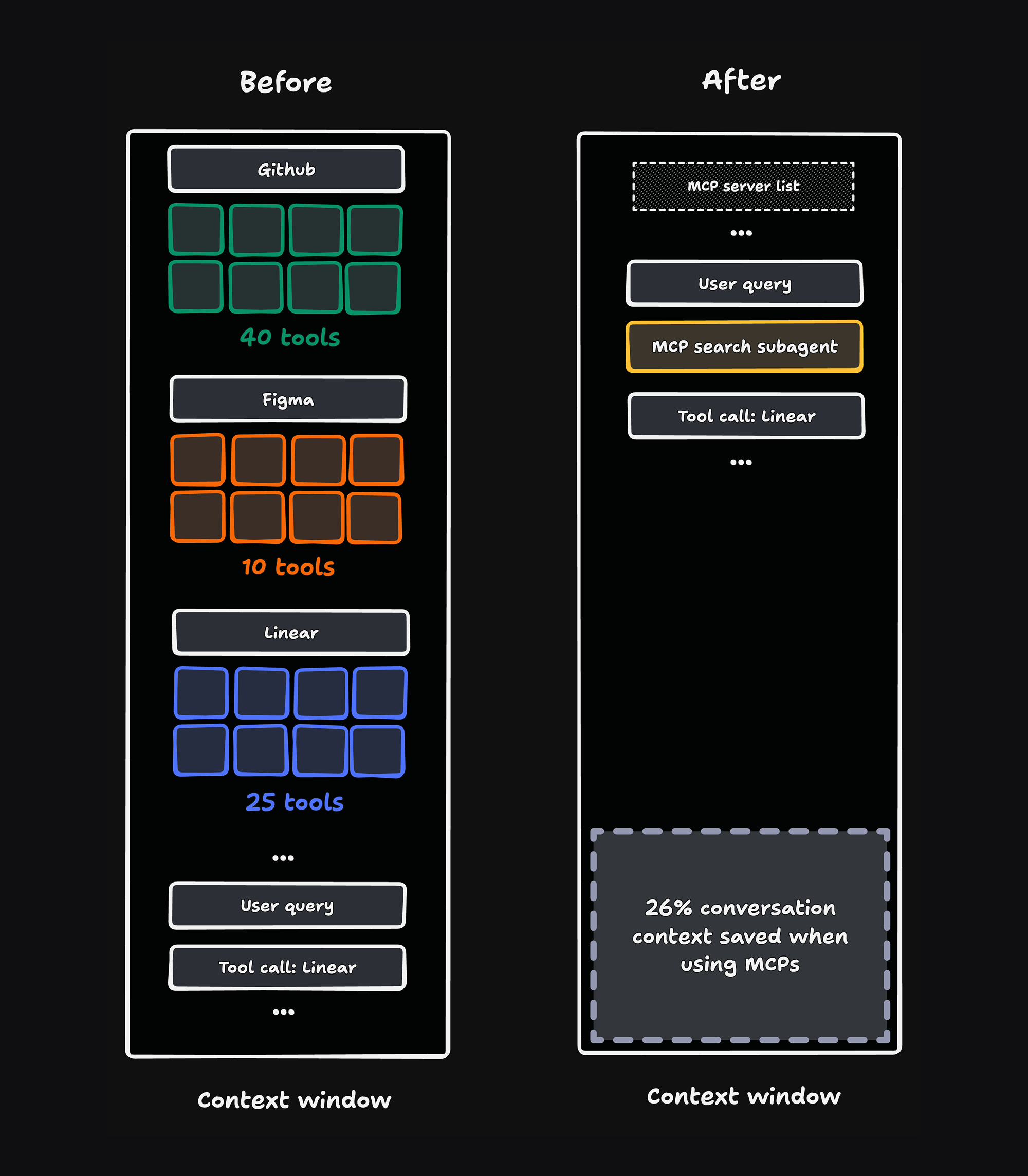
We’ve optimized Warp's agent to use MCP more efficiently. MCP usage in Warp now uses 26% fewer tokens for tasks that rely on MCP context, and 10% fewer tokens when MCP context is supplied but unused. And these improvements were made for every AI model we support, without sacrificing quality.
Here's how we built a model-agnostic MCP search subagent that automatically discovers only the tools and resources your task actually needs.
What is MCP?
MCP is a standard that defines how LLM agents interact with one or more user-configurable servers, which provide tools and resources beyond your codebase. For example, you can install an MCP server that allows access to your issue tracking server, allowing the agent to file or update bug reports. Or you might configure MCP access to your local Postgres instance, allowing the agent to run queries against your development database.
Warp has further invested in MCP with our one-click installation process, letting you authenticate with popular servers including GitHub, Linear, Figma, and more without manual configuration. We also added MCP server sharing, letting you share MCP configurations with your entire team. And in Warp, MCP usage is automatic—install MCP servers once, and Warp’s agent will automatically decide when it is appropriate to use them.
Users who reach for MCP quickly become power users, plugging in multiple servers for various workloads. In our previous implementation, this high usage had a detrimental impact on conversation quality and efficiency. We would preload all MCP tools and resources into the context window, which could bloat the context window by as many as 50k tokens from these definitions alone. This cost compounds over longer conversations and ultimately distracts the agent from the core task.
Notably, we also found that about 90% of tasks that have MCP context available don’t actually need them to complete the task, and tasks that do need it only typically use a few tools. This ultimately led us to question whether MCP context actually needed to be statically front-loaded into the context window.
The MCP search subagent
With this data in mind, we designed an MCP search subagent that dynamically searches through all of your MCP servers’ tools and resources, then selects the most relevant ones. The subagent approach isolates the responsibility of looking for the right MCP context to a fresh context window, which can be served by a smaller, cheaper model than the one powering the main agent. Here’s how it works:
- The main agent receives a condensed list of the available MCP servers and a brief description of each, rather than a list of all tools and resources.
- The main agent invokes the search subagent to perform a natural-language, LLM-mediated search over the tools and resources of all the MCP servers.
- The subagent returns only the relevant tools and resources.
- The main agent can then use relevant tools and resources to complete the task.
For conversations that use MCP extensively, this reduces context to only the subset that is relevant to your task.

This optimization delivered measurable conversation cost savings:
- A 10% improvement in mean cost for conversations where MCP tools were available
- A 26% improvement in conversations where MCP tools were actually used
Since we changed how the agent discovers what MCP tools and resources are available, we needed to ensure that this new approach did not degrade our agent’s ability to use MCP effectively. We tested this using an LLM-as-judge evaluation and saw no significant difference in the agent’s ability to make use of MCP context when relevant.
We also investigated alternative solutions, like bespoke tool search capabilities from model providers, but found our solution more complete and optimized for MCP. Building a model-agnostic solution means every model you use in Warp benefits from these improvements.
Try out MCP in Warp now
MCP context search tool is now rolled out to all production users. If you’re already using MCP servers, you’re automatically benefiting from these optimizations. As MCP continues to be adopted as a standard protocol for agents to retrieve external context, we believe this optimization will have a significant impact in minimizing user costs while maximizing conversation quality. You can learn more about how to install and use MCP servers in Warp in our docs.
Features like the MCP search tool are the work of our talented AI Quality Team engineers, including Suraj Gupta, Daniel Peng, David Stern, and myself, Matthew Albright. If you want to join us in solving ambitious and complex AI problems like this, we'd love to hear from you. Reach out to us at recruiting@warp.dev.
Related articles

Jun 29, 2026 · 5 min
How to build a cloud software factory - add spec-driven development skills
This is my second post in a series on how to build out a fully automated cloud software factory. In this post, I’ll show how you can add spec-driven development for issues that are too complex or ambiguous to one-shot. The goal of these posts is to build a fully working...

Jun 25, 2026 · 7 min
How to build a cloud software factory - the automatic triage skill
This post is the first in a series I’m doing on how to set up your own cloud software factory using skills and loops. It’s easier than it sounds to get something simple and effective running so you can start to automate significant parts of your team’s development flow.

Jun 18, 2026 · 4 min
Building a skill optimization loop
This post shows how to create a loop with automated feedback that an agent can run to optimize its own Skills. It uses an automated grader with computer use to assess how well a Skill is performing, and then iteratively improves the Skill.