SWE-bench is the primary benchmark for evaluating LLMs and AI agents on coding tasks. It assesses a system’s ability to fix problems pulled from real-world GitHub issues on large, complex open-source codebases. Using these realistic coding tasks lets SWE-bench evaluate several factors. There’s the LLM itself, of course, but other aspects of the system have significant impact on results: the user and system prompts, the tools given to the model, and even how code and other context is formatted, to name a few.
We evaluated Warp’s agent abilities on SWE-bench Verified, and found that it was able to resolve 71% of instances autonomously – putting it in the top 5 on the leaderboard!
Most excitingly for us, this involved minimal changes from the user-facing product, meaning that this performance translates to day-to-day software development. This demonstrates that high-quality results are still possible with a single-agent, single-attempt architecture. We explored a set of multi-agent approaches, such as dedicated testing and reasoning agents, an agent for planning and context gathering, and a best@k system that asked Warp to produce and choose between multiple diffs. However, the most consistent, reliable architecture remained our single primary agent. Quality and reliability improvements to that agent all contributed to both the success rate at resolving instances and the end-user experience. For example, it was particularly fruitful to iterate on our LLM failover chain, which is used to recover from both invalid model responses and production outages.
Architecture
Warp uses a single-agent architecture, with the following set of tools:
edit_files– this allows the agent to make search/replace edits across multiple files at once. We’ve found that this enables the agent to efficiently make bulk updates, such as when refactoring or renaming a variable.create_file– having a dedicated file-creation tool allows us to simplify instructions on how to useedit_files, reducing ambiguity. It also allows stricter path validation, as the agent’s intent is clear.- Tools to search and read files (
grep,find, andcatanalogues). Having specialized tools for these tasks let us manage the agent’s context window more effectively. For example, we limit the number of lines shown for large files, allowing the agent to “scroll” while maintaining a reasonable context window size. run_command– this allows the agent to execute any shell command. It also provides metadata used to assess command safety, and to support interacting with long-running commands (see below).
The agent is given the ability to record and update a TODO list. Optionally, it can be guided to create TODOs for itself up-front, after gathering the required context. This provides a lightweight planning mechanism, and works well with prompting in step-by-step form.
Warp also supports MCP and web search, though those capabilities were disabled for our SWE-bench Verified evaluation.
To execute SWE-bench instances, we gave the agent the PR description as a user prompt. It then had one attempt to autonomously explore the repository, create and run tests, and solve the problem. We explored a best@k approach, where the agent was instructed to produce multiple solutions and choose the most promising one, but did not use this in our final submission.
Long-running commands
The most novel aspect of Warp’s run_command tool is its support for long-running alt-screen or pager commands, such as REPLs, git log output, or even vim. If the agent executes a long-running command, we provide it with a different set of tools that allow passing input to that command and processing updated output. Notably, this does not use a separate agent – we’ve found that using the same agent with a restricted tool set is more reliable due to context window preservation.
In our analysis of SWE-bench attempts, we’ve seen the agent use this capability to:
- Read Python documentation using the
helpbuiltin - Use
ctrl-cto interrupt slow-running tests when the full results weren’t needed - Inspect repository history to gather context about a change
Allowing the agent to interact with long-running commands also prevents it from getting stuck when unexpectedly triggering the terminal pager. This is a common failure mode with git commands in particular, where the agent runs a seemingly-safe command like git log and is then unable to proceed.
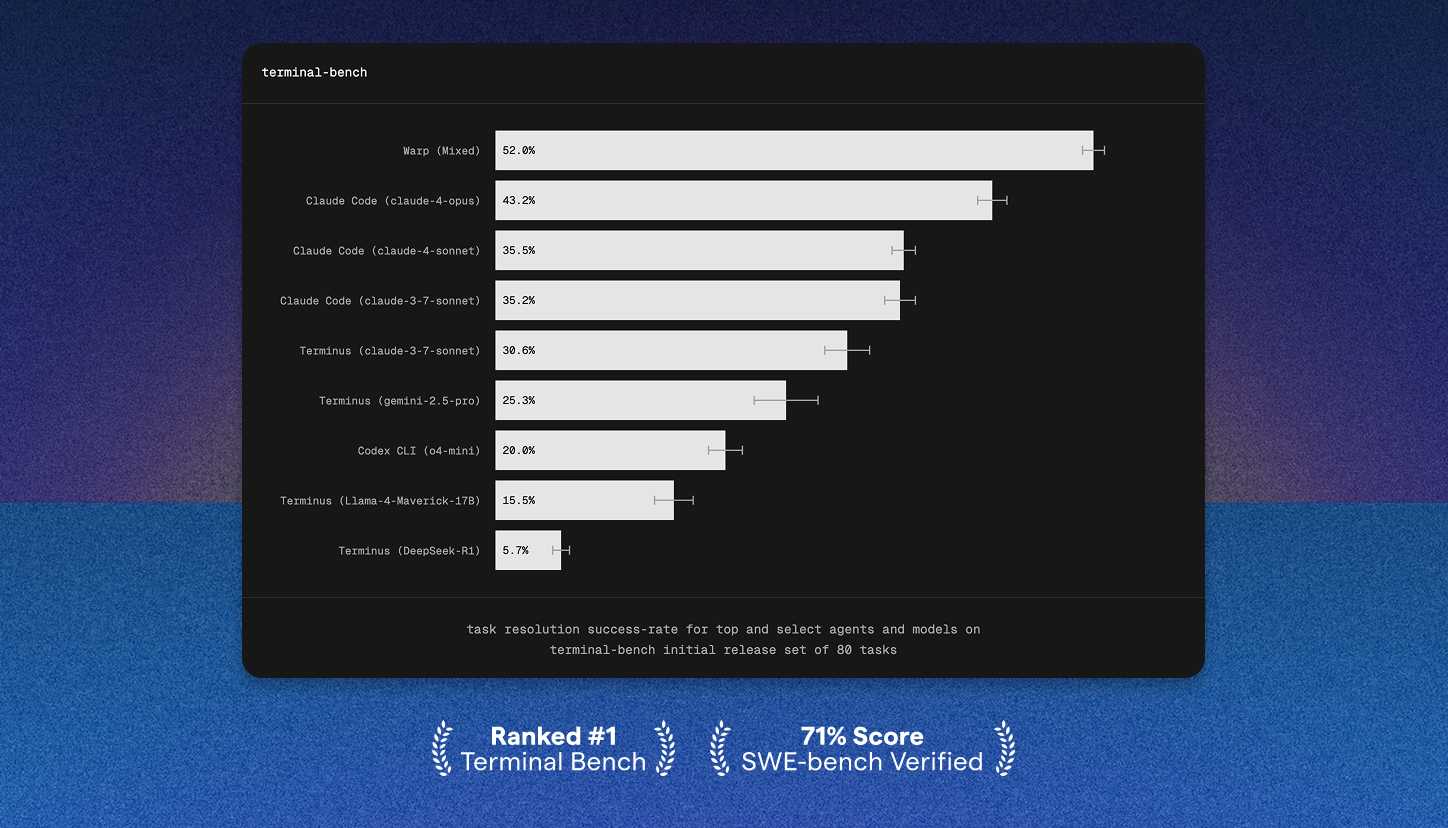
This was also a significant factor in Warp’s terminal-bench performance.
Editing
While the core string-replacement editing tool is simple, we found that giving the LLM affordances improved reliability significantly. If exact string matching fails, we attempt an indentation-agnostic match followed by a Jaro-Winkler string similarity search. This allows applying edits where the search string has incorrect comments or whitespace.
If an edit cannot be applied, the agent is informed why and may optionally retry. Common reasons for failed edits were the agent misunderstanding which directory it’s in or duplicating path components – encouraging the use of absolute paths and providing detailed failure information allows the agent to recover.
Earlier versions of Warp used structured XML output for edits, rather than the tool-calling capabilities of LLM providers. This was so that the LLM would not need to produce accurately-escaped text, particularly for strings and whitespace. As models improve, we found that direct tool calling is now sufficiently reliable, especially when combined with server-side retries of failed calls. Edits are still the most common failed tool call, however, and this remains an area for improvement.
Model Choice
Warp has long supported a mix of models, with an auto configuration that chooses the most appropriate LLM for a task. In production, we also use this model-choice infrastructure to fall back from one LLM to another. This smooths over provider outages and latency, occasional rate-limiting, and other interruptions. Invalid responses from the model itself, such as malformed tool calls, are also candidates for retry. We originally attempted to retry with the same model, and found that this often produced repeat failures. Instead, for our SWE-bench evaluation, we found that the most effective chain was:
- Anthropic Claude 4 Sonnet
- Anthropic Claude 3.7 Sonnet
- Google Gemini 2.5 Pro
- OpenAI GPT-4.1
Evaluation Harness
The fact that Warp is a GUI desktop application presented a challenge to attempting SWE-bench instances at scale. Fortunately, we had previously built a Rust integration-testing framework. This library is deeply integrated with Warp’s UI framework, and allows simulating user input, inspecting internal application state, and waiting for commands or tasks to complete. After adapting this framework to also run in Docker containers, we could use it to evaluate instances by submitting them as user prompts. Any requested actions by the agent were auto-approved, and we collected and tested the diff after it finished executing. Notably, the evaluation harness is able to execute all but 3 of the 500 SWE-bench Verified instances. Reaching this level of coverage required significant debugging effort from the team, largely assisted by Warp itself.
This harness allowed for many different run configurations:
- Local execution of individual eval cases, for rapid iteration and reproducing errors
- Highly-parallel remote execution, for generating predictions on the full dataset
- Limited-parallelism remote execution, for getting meaningful experiment results Remote execution used GitHub Actions, backed by Namespace, and was built as a CI pipeline we intend to use for other evaluations and regression testing. In particular, it allows targeting arbitrary versions of Warp’s client and server, as well as choosing specific repositories or tests to execute. We’re especially grateful to Namespace for their support in scaling out this infrastructure.
To produce trajectories, we relied on existing debugging infrastructure that captured agent inputs and outputs, along with metadata about retries, LLM fallbacks, and file-state management. By converting those debug traces to human-readable text, we were able to inspect failing instances and also document agent behavior for submission.
Abhishek, an engineer at Warp, shares how Warp sets up their SWE-bench evaluation harness
Conclusions
Warp's performance on SWE-bench Verified demonstrates that:
- Single-attempt architectures are competitive at coding tasks. This is particularly significant for user-facing systems, where the additional latency of multi-attempt approaches may be untenable.
- The inherent variability of LLMs requires that agentic systems include recovery mechanisms. Reporting tool-call failures back to the LLM, falling back to alternate models, and putting reasonable restrictions on tool use all increase the odds that an agent will accomplish its task.
- Within a single agent, context-dependent tool availability is a promising direction for constraining agent behavior while retaining full context.
We're excited to continue improving Warp and to see what our users build with it!